This time, I dove deep into Google’s latest multimodal AI model - Gemma3n - to understand what makes it tick.
Recently, Google released Gemma3n, and honestly, it caught my attention immediately. Unlike the usual incremental updates we see in AI models, this one felt different. It’s not just about making things bigger or faster - it’s about fundamentally rethinking how AI can work on the devices we carry every day.
The “n” Makes All the Difference 🔗
What struck me first about Gemma3n is that little “n” at the end. It’s not just marketing - it represents a genuine architectural revolution. While traditional language models like GPT or earlier Gemma versions focused solely on text, Gemma3n natively handles:
- Text: Supporting an impressive 140 languages
- Vision: Processing images with resolutions from 256x256 to 768x768 pixels
- Audio: Real-time speech understanding generating tokens every 160ms
- Video: Frame-by-frame analysis at 60 FPS
This isn’t achieved through simple model concatenation but through sophisticated architectural innovations that I found fascinating to dig into.
MatFormer: The Nested Genius 🔗
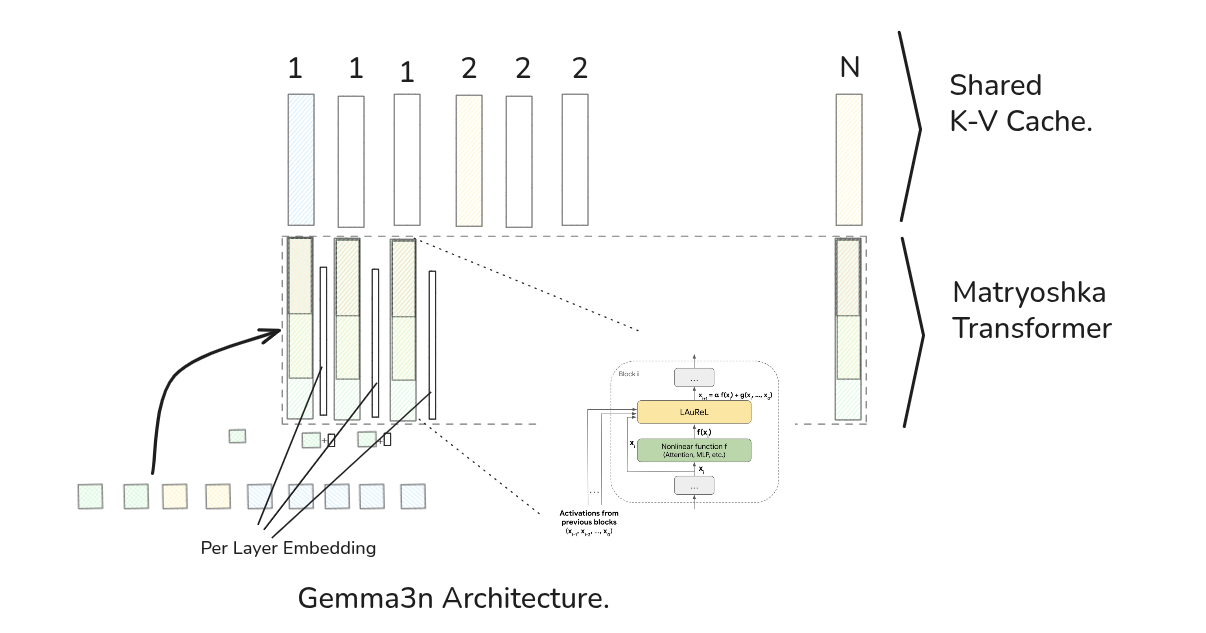
At Gemma3n’s core lies something called MatFormer (Matryoshka Transformer) - and the name perfectly captures what it does. Think of Russian Matryoshka dolls where each larger doll contains smaller, complete dolls inside. MatFormer works similarly, containing multiple fully-functional models within a single larger architecture.
This concept extends Matryoshka Representation Learning from just embeddings to all transformer components, enabling:
- Elastic Inference: Dynamically adjust computational load based on device capabilities
- Selective Parameter Activation: Load only necessary parameters for specific tasks
- Graceful Degradation: Maintain functionality even with limited resources
Gemma3n comes in two variants that showcase this efficiency:
- E2B: 5B total parameters, operating like a 2B model (2GB memory)
- E4B: 8B total parameters, operating like a 4B model (3GB memory)
The “effective parameter” concept is crucial here - while the raw parameter count is higher, architectural innovations allow the models to run with significantly lower memory footprints. (Introducing Gemma 3n: Developer Guide)
How Gemma3n Handles Audio 🔗
The audio processing pipeline fascinated me. It employs a Conformer architecture based on Google’s Conformer: Convolution-augmented Transformer for Speech Recognition research, which combines:
- Convolutional Subsampling: Efficient audio feature extraction
- Cumulative Group Normalization: Specialized for streaming audio data
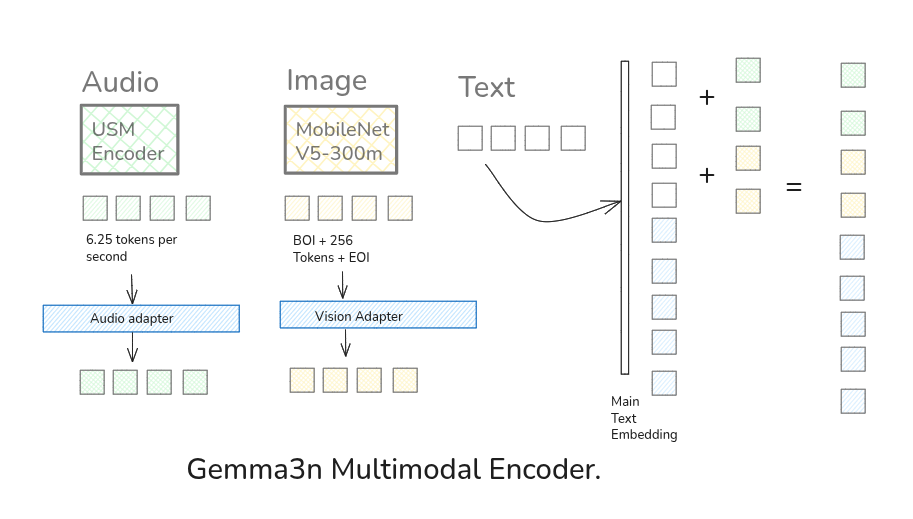
- Universal Speech Model Foundation: Built on Google’s Universal Speech Model (USM), generating audio tokens every 160ms (approximately 6.25 tokens per second)
The Conformer architecture achieves state-of-the-art performance by modeling both local and global dependencies efficiently, with the USM foundation providing multilingual speech understanding across 300+ languages using 2B parameters trained on 12 million hours of speech data.
Vision Processing That Actually Works on Phones 🔗
The vision system utilizes MobileNet-V5-300M, Google’s latest efficient vision encoder that builds upon the MobileNet family (MobileNets V1, V2, V3). What impressed me most:
- Multiple Resolutions: Natively supports 256x256, 512x512, and 768x768 pixels
- Fixed Token Output: Each image produces exactly 256 tokens regardless of input resolution
- Token Structure: Images are wrapped with Begin-of-Image (BOI) and End-of-Image (EOI) tokens (258 total tokens per image)
- High Throughput: Processing at 60 frames per second on Google Pixel devices
- Advanced Architecture: Built on MobileNet-V4 blocks including Universal Inverted Bottlenecks and Mobile MQA
- Quantization Optimization: 13x speedup with quantization techniques
Note: Google has announced that a dedicated MobileNet-V5 technical report covering architecture details, data scaling strategies, and advanced distillation techniques is forthcoming.
The Multimodal Bridge 🔗
The Multimodal Embedder (Gemma3nMultimodalEmbedder) serves as the crucial bridge between modalities:
[Text Tokens] ──┐
├──► [Unified Embedding Space] ──► [Language Model]
[Audio Tokens] ──┤
│
[Vision Patches]─┘
This component ensures all modalities operate in the same embedding space, enabling seamless cross-modal reasoning.
Text Model Innovations That Caught My Eye 🔗
Beyond multimodal capabilities, Gemma3n incorporates several advanced techniques for improved text processing that I found particularly clever:
Alternating Updates (AltUp) 🔗
The Team Analogy: Imagine a team of experts trying to solve a complex problem. One expert is the “main worker” (the active model path), who will perform a deep, detailed calculation. The other experts are “predictors,” who make a quick guess based on the initial information.
- Predict: Before the main worker starts, all the predictors quickly write down their best guess
- Activate: The main worker then performs the full, complex task (the attention and MLP layers)
- Correct: Once the main worker has the correct answer, they share it. The predictors then look at the difference between their initial guess and the correct answer and update their own knowledge
This “predict-correct” cycle helps all the “experts” (model states) learn more efficiently from the work of one, speeding up overall convergence and improving performance.
The Gemma3nTextAltUp module implements this predict-correct cycle based on the Alternating Updates for Efficient Transformers research from Google Research, enabling up to 87% speedup relative to dense baselines at the same accuracy.
Learned Augmented Residuals (Laurel) 🔗
Highway Analogy: Think of the main information flow in a transformer as a wide, multi-lane highway (the residual connection). It’s effective but carries a lot of traffic.
Laurel adds a small, efficient “scenic bypass” next to the main highway. This bypass is a narrow road (a low-rank bottleneck), so it doesn’t require much infrastructure (parameters). However, it can capture some extra, useful information or learn a small, helpful correction that the main highway might miss.
At the end of the block, the traffic from the main highway and the scenic bypass merge, resulting in a richer, more nuanced final output without significantly increasing the model’s size.
Gemma3nTextLaurelBlock implements this parallel pathway based on LAuReL: Learned Augmented Residual Layer, achieving 60% of the gains from adding an extra layer while only adding 0.003% more parameters, and can improve LLM performance by 2.54% to 20.05% with minimal parameter overhead.
Advanced Optimization Techniques 🔗
Gaussian Top-K Sparsity - Orchestra Conductor Analogy: Imagine an orchestra conductor who wants to create the most impactful sound. Instead of having every single musician play at full volume (a “dense” activation), the conductor decides to focus the energy.
The conductor doesn’t just pick a fixed number of musicians to play. Instead, they listen to the statistical properties of the current musical piece (the mean and standard deviation of neuron activations). Based on this, they set a dynamic “importance threshold.”
Only the musicians playing louder than this threshold (the “top-k” most active neurons) are asked to continue playing. Everyone else is asked to rest. This makes the resulting music (the model’s output) clearer and saves the other musicians’ energy (computation), making the whole process more efficient.
This builds on research showing that transformer activations are naturally sparse, with enforced Top-K sparsity providing better calibration and noise robustness.
Key-Value Sharing - Meeting Notes Analogy: Imagine a long meeting with many speakers (transformer layers). Each speaker needs to refer to what has been said before (the sequence of tokens). The “Key” and “Value” tensors are like the detailed notes each speaker takes about the past conversation.
In a standard model, every single speaker takes their own, new set of notes from scratch, which uses a lot of paper (memory).
With KV Sharing, the process is smarter. An early, experienced speaker (e.g., Layer 4) takes very good, general-purpose notes and saves them to a shared whiteboard (the KV Cache). Later speakers (e.g., Layer 20, 21, 22), instead of taking their own notes, simply walk up to the whiteboard and use the notes already written by Layer 4. This saves a huge amount of paper (memory) and time (computation), especially in a very long meeting (long sequence inference).
This technique is inspired by Cross-Layer Attention research, which demonstrates 2x KV cache reduction while maintaining accuracy.
Dual RoPE: Separate Rotary Position Embeddings for global and local attention patterns, providing more flexible positional understanding. (RoFormer: Enhanced Transformer with Rotary Position Embedding)
Performance Optimizations 🔗
Key memory optimization techniques include:
- Per-Layer Embedding (PLE) Caching: Embedding parameters loaded on CPU instead of accelerator memory
- KV Cache Sharing: 2x improvement on prefill performance
- Conditional Parameter Loading: Load only necessary components for specific tasks
Gemma3n employs a sophisticated mix of attention mechanisms:
- Full Attention Layers: For comprehensive context understanding
- Sliding Window Attention: For efficiency in long sequences
- Dynamic Switching: Based on computational resources and sequence characteristics
Real-World Impact 🔗
Gemma3n’s efficiency enables previously impossible applications:
- Smartphone AI Assistants: Full multimodal reasoning on mobile devices
- Offline Creative Tools: Image and audio processing without cloud connectivity
- IoT Intelligent Endpoints: Smart devices with advanced reasoning capabilities
- Privacy-Focused Applications: Sensitive data processing without cloud transmission
With support for 140 languages and multimodal understanding in 35 languages, Gemma3n democratizes AI access globally, particularly in regions with limited cloud connectivity. For implementation details and examples, see the Gemma 3n on Hugging Face.
Token Economics 🔗
What I found particularly interesting were the token usage patterns:
Audio Processing:
- Rate: 6.25 tokens per second
- Granularity: 1 token every 160ms
- Efficiency: Very economical for continuous audio
Vision Processing:
- Tokens per image: 256 tokens (fixed, regardless of resolution)
- Total with markers: 258 tokens (including BOI + EOI tokens)
- Resolution flexibility: Same token count for 256×256, 512×512, or 768×768 images
- Processing speed: Up to 60 FPS capability
This predictable tokenization makes Gemma3n incredibly practical for real-world deployment, where you need to plan memory usage and computational costs upfront.
This analysis is based on Hugging Face source code implementation and Google’s official documentation, co-written with AI models to synthesize technical insights from multiple sources.