Insight into building AI-based Python tutor for kids.
Tino: Coding Your Way Home! 🔗
Concept:
Tino is a unique board game that blends classic board game mechanics with the power of coding. Players take on the role of Tino, a lovable dog who needs your help to navigate his way back home. But here’s the twist: you won’t be using dice or spinners! Instead, you’ll be guiding Tino using real Python code!
Gameplay:
- The game board is filled with obstacles and items to collect.
- Players start by writing Python code to control Tino’s movements.
- Your code can include commands like
forward(),left(),right(), andjump()(to collect items). - With each turn, the player executes their code, watching Tino follow their instructions on the board.
- The goal is to reach Tino’s house within a set number of turns or by collecting specific items scattered around the board.
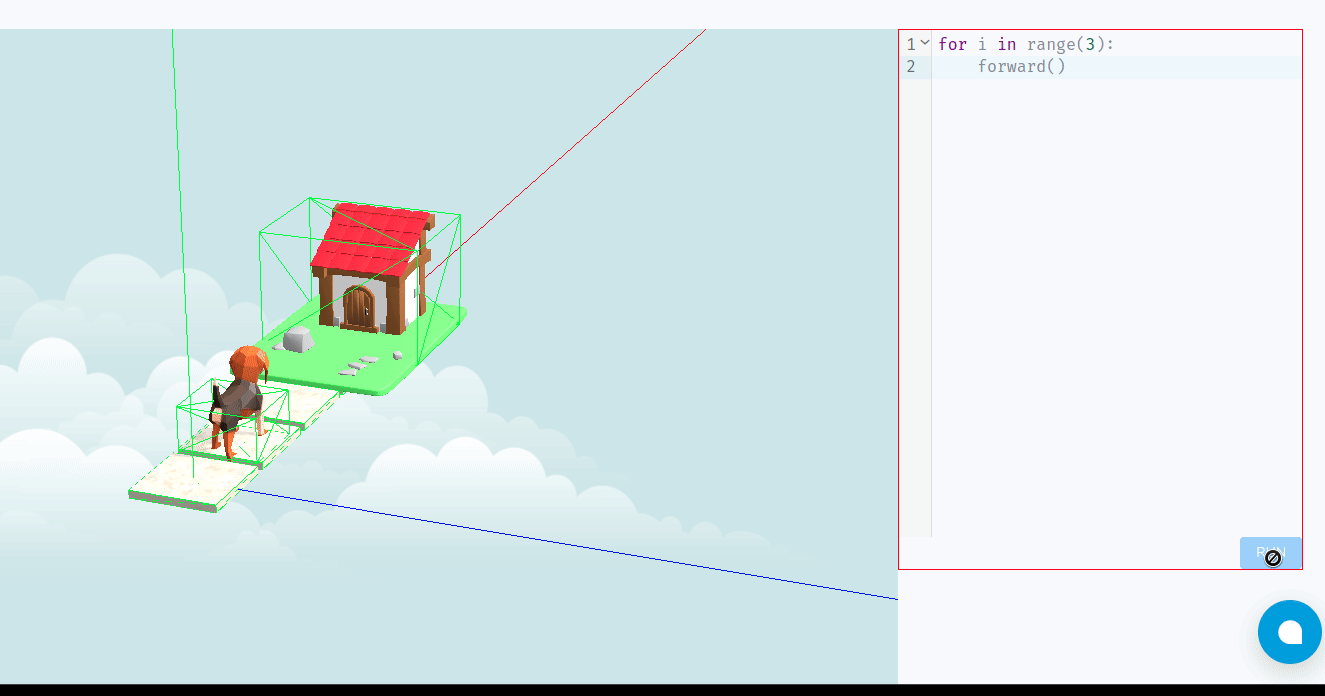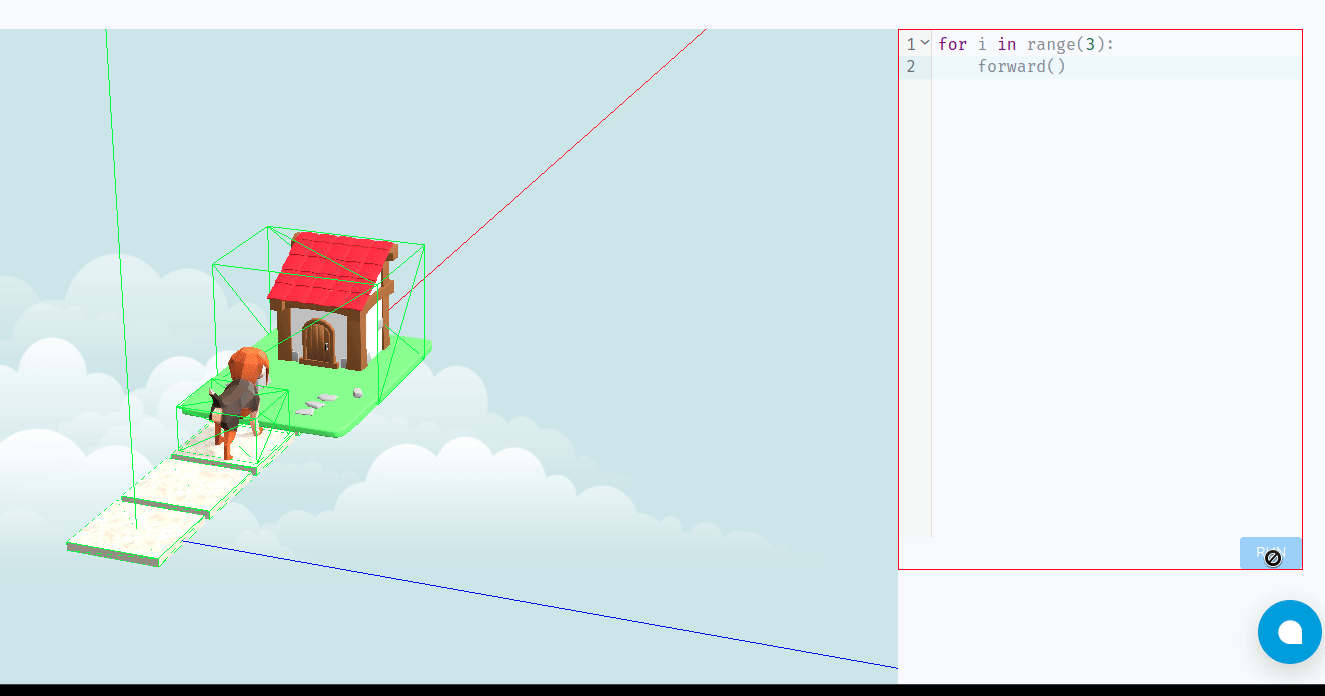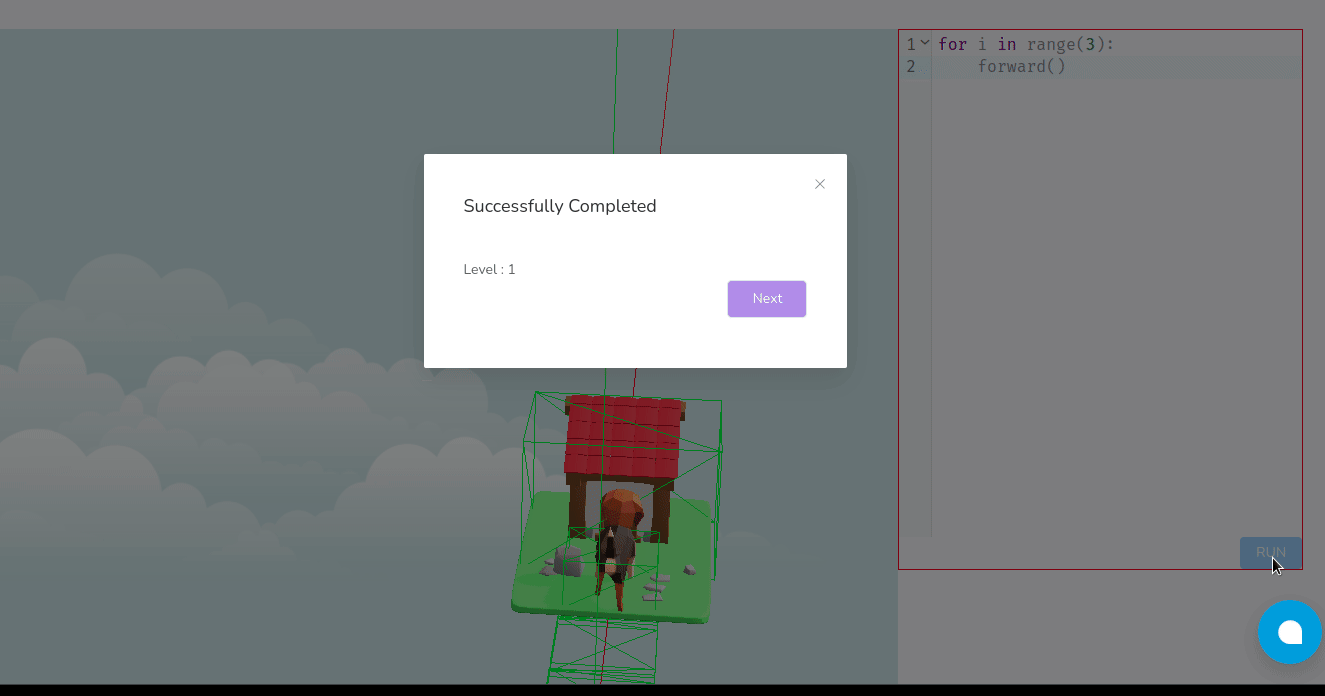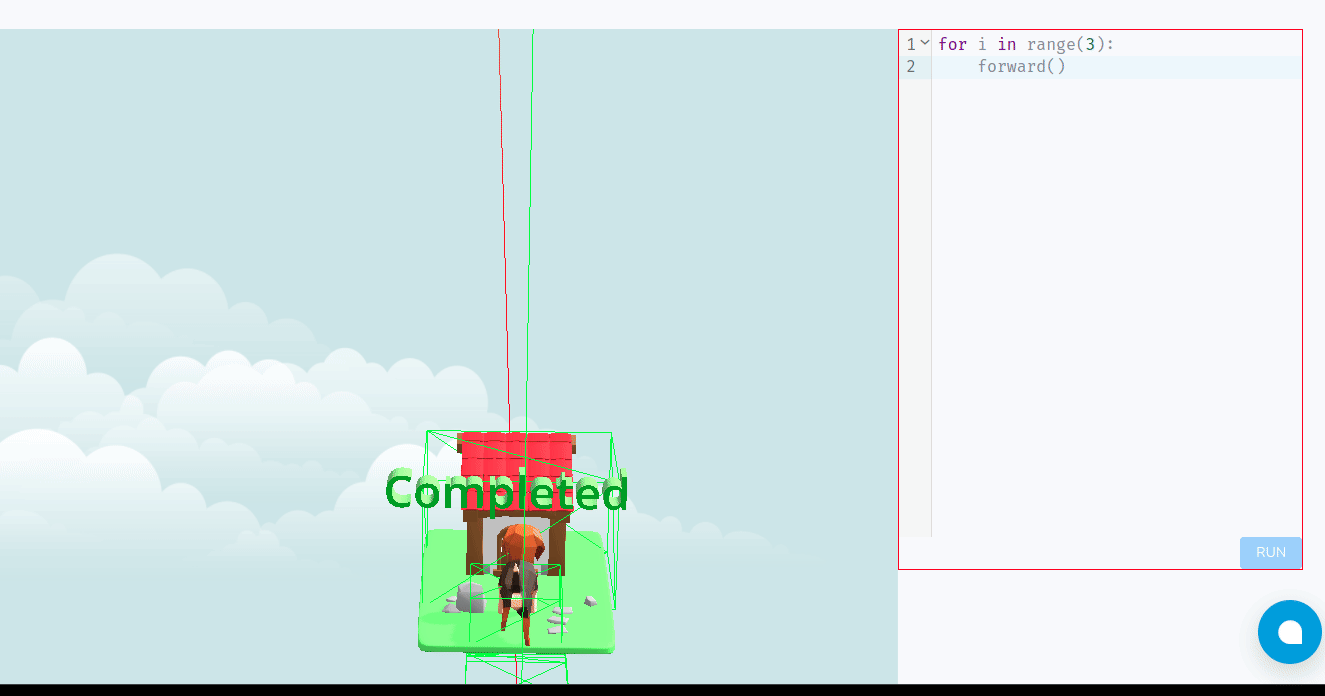
Learning Through Play:
- Tino gamifies the process of learning to code, making it fun and engaging.
- Players start with simple commands, gradually building their coding skills as they progress through the game.
- The game can be designed with increasing difficulty levels, introducing new coding concepts like loops and conditional statements as players advance.
AI teacher? 🔗
In Tino’s case, the idea is to have a chat-based AI teacher guide you through solving board puzzles, making you a coding whiz.
Text-Based LLMs
These LLMs are trained on vast text corpora, enabling them to interact conversationally. However, their understanding is limited to textual patterns. While they can recognize the word ‘dog’ in text, an image of a dog wouldn’t register as such.
Challenges
Here onwards things get a bit technical :)
-
Understanding the Game Board: A Key Challenge One of the initial challenges for Tino’s AI instructor lies in comprehending the game board’s layout. This entails not only grasping the fundamental movement rules but also possessing a spatial awareness of the board itself. The AI must be able to identify the placement of individual tiles, Tino’s starting position, and crucially, the location of his house. Without this spatial understanding, effectively guiding the user through the game becomes a significant obstacle.
-
Spatial Reasoning: A Hurdle for LLMs While Large Language Models excel in manipulating language and can readily generate Python code, they often encounter difficulties with spatial reasoning. This refers to the ability to understand the arrangement and relationships between objects within a spatial environment. In Tino’s context, this translates to visualizing the board, Tino’s movements, and strategically planning the most efficient path to his house. Bridging this gap and equipping the AI with this crucial skill is a key area of development.
-
Beyond Code Generation: Fostering Problem-Solving Solving Tino’s puzzles extends beyond simply writing Python code. It necessitates planning and strategizing, requiring the ability to think several steps ahead before translating those thoughts into code. The ideal AI instructor wouldn’t just translate your ideas into code, but also guide you through this critical problem-solving process, fostering valuable cognitive skills.
Here, we explore several methodologies for conveying game board information to Tino’s AI instructor, a Large Language Model (LLM).
- Textual Representation with Pathfinding Algorithms:
One initial approach involved representing the board as a textual description derived from a Breadth-First Search (BFS) or Depth-First Search (DFS) traversal. While seemingly straightforward, empirical testing yielded less-than-optimal results. However, a recent research paper, “Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models” (arxiv:2404.03622), presents a promising avenue for further exploration in future posts.
- Graph Autoencoders and Textual Embeddings:
Another strategy considered leveraging Graph Autoencoders. These models encode the board’s information as a numerical representation and then project it into a textual space. This necessitates the development of a CLIP-like system (Contrastive Language-Image Pre-training) specifically designed for graphs – a concept lacking readily available implementations. Due to this, this approach is earmarked for future investigation.
- Multimodal LLMs and Image Representation:
A more straightforward approach involves utilizing Multimodal LLMs capable of image comprehension. The game board could be represented as an image for the LLM to interpret. Preliminary testing with Gemini, a large language model, yielded promising initial results
The first trial gave great results it was able to figure out there was a dog, house and bone. It was a bit of a surprise.
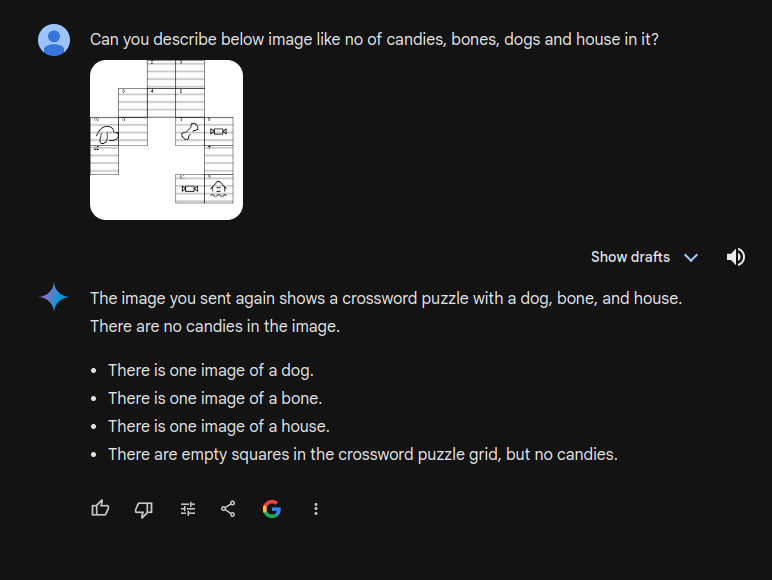
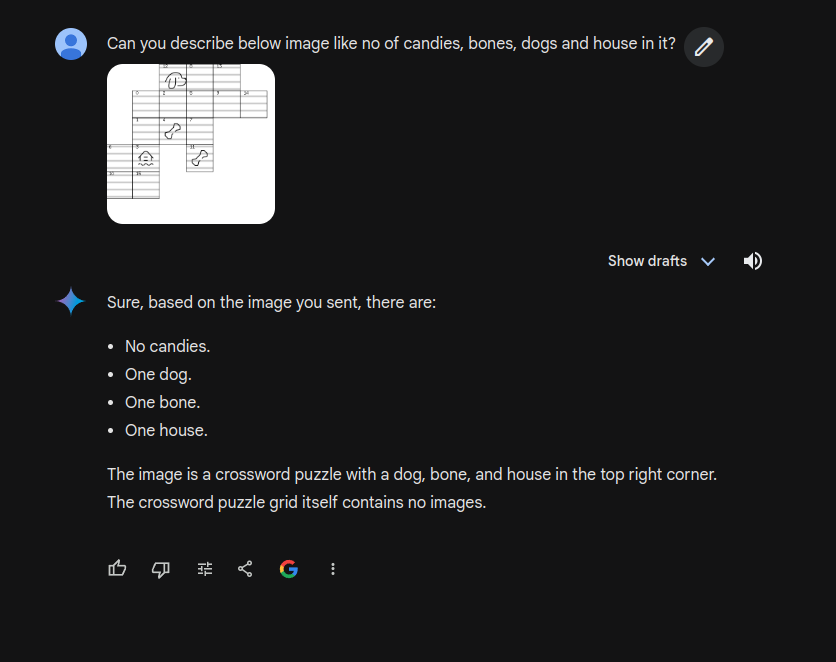
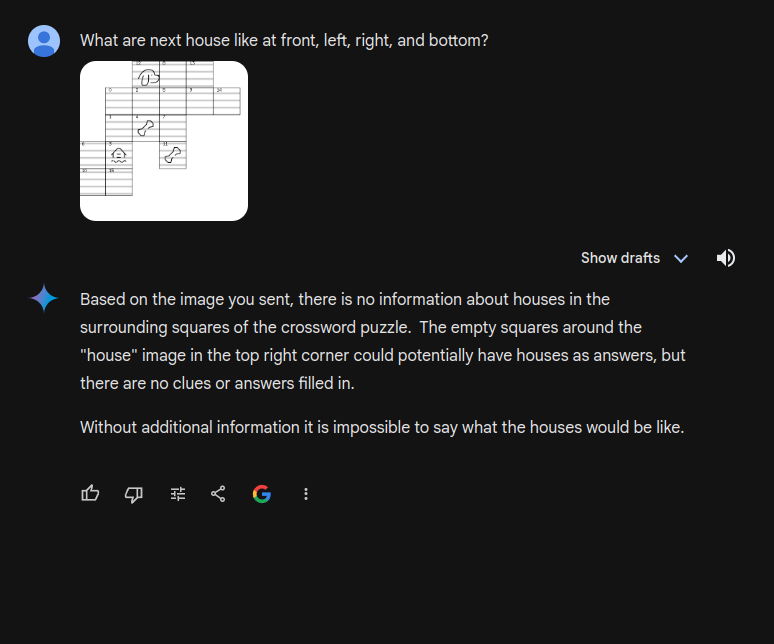
What next steps be?
- Fine-tuning Vision-Enabled LLMs:
The first approach involves fine-tuning existing vision-enabled LLMs, such as Gemini-Vision or GPT4-Vision, specifically on our game board dataset. This targeted training would allow these models to develop a deeper understanding of the visual elements within Tino’s game board.
- Leveraging a Smaller Vision-Enhanced LLM:
Our research led us to a more focused architectural approach – a smaller LLM equipped with a visual processing module (as outlined in the referenced paper: “Unifying Vision-and-Language Tasks via Text Generation”). This architecture, depicted in the provided image
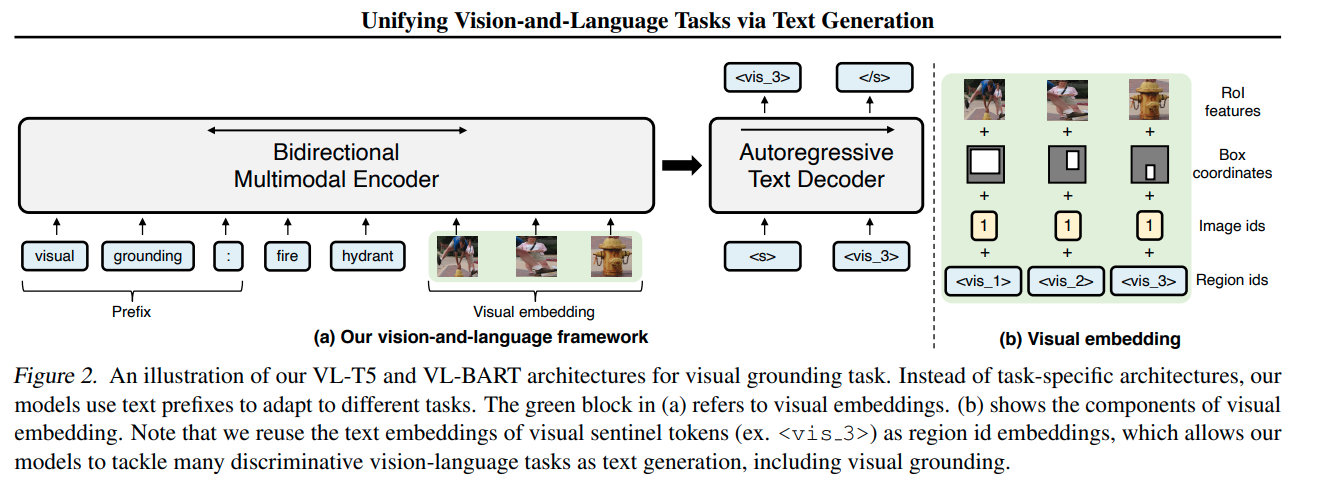
Synthetic dataset
While we currently have 12 designed levels for the board game, this wouldn’t be sufficient to effectively fine-tune a Large Language Model (LLM) for spatial reasoning tasks. LLMs typically require vast amounts of labeled data to excel.
To overcome this hurdle, we opted to generate a synthetic dataset of 5,000 game boards. This dataset incorporates labels based on our initial experiments with Gemini.
To illustrate the structure of the synthetic data, we’ve included a sample board map alongside its corresponding labels
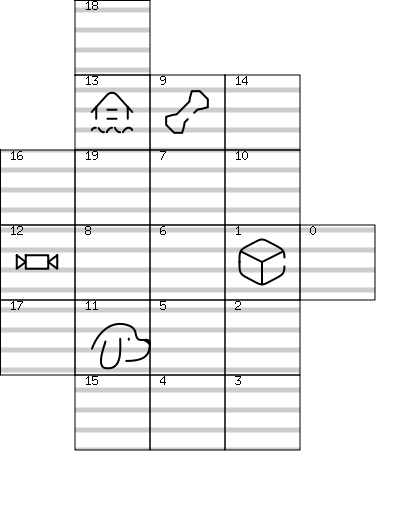
{
"ImagePath": "dataset/images/rand_board_map_11.png",
"CountDesc": "Board has 1 bones, 1 candy, 1 blocks, 1 house, 1 tino counting total of 20 tiles",
"NeighborDesc": "From tino's current position,1. if turn left and forward will move to has a empty tile in it2. If turn right and forward will to has a empty tile in it.3. If step forward will move to will move to void tile and drop off4. If I step backward will move to will move to void tile and drop off",
"Python": "forward()\nleft()\nforward()\njump()\nright()\nright()\nforward()\nforward()\nleft()\nforward()\nforward()\njump()\nleft()\nforward()\n"
}
We skipped other labels that are not relevant for part 1 of this post.
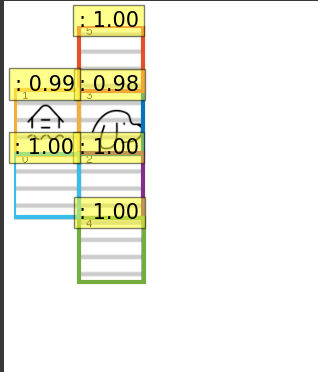
Fine-tuning DETR
Pretrained DETR models weren’t able to detect
- our object classes like dog, and bone vector images.
- Had issues detecting smaller regions especially when the dog & other objects are on the same tile. And we could optimally finetune DETR model against our synthetic dataset, below are the evaluation results,
Running evaluation...
0%| | 0/301 [00:00<?, ?it/s]
Accumulating evaluation results...
DONE (t=1.03s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.903
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.961
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.958
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.903
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.661
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.868
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.932
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.932
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
sample inferences made,
Let’s finetune LLM
-
We used almost the same architecture as VL-T5.
-
We trained this on A100 x1 GPU on paperspace for 60 epochs. Training took about 16 hours, with the T5 model declare-lab/flan-alpaca-base using huggingface transformers.
-
Here are the results,
{
"epoch": 30.0,
"eval_gen_len": 1.0,
"eval_loss": 0.009672305546700954,
"eval_rouge1": 92.6755,
"eval_rouge2": 85.0584,
"eval_rougeL": 87.6622,
"eval_rougeLsum": 89.6535,
"eval_runtime": 1473.8198,
"eval_samples_per_second": 2.296,
"eval_steps_per_second": 0.287
}
- And less cryptic measures of how well our model performs on the counting tiles and objects task,
Differnce in count between Label & Pred | Percentage |
--------------------------------------------------------------------------
0 (No errors exact match) | 71.5029 |
--------------------------------------------------------------------------
1 | 25.5208 |
--------------------------------------------------------------------------
2 | 2.7901 |
--------------------------------------------------------------------------
3 | 0.1674 |
--------------------------------------------------------------------------
and in the case of the finding neighbor’s task, it achieved about 0.1533 accuracy. We measure accuracy by rudimentary exact text match, actual real accuracy would a higher.
In Part 2 of the post, we will look into how well it performs BFS, writing Python code that solves a given puzzle when augmented with Chain of thought reasoning.